.
Introduction
Is your VOIP system based on userspace applications ? What about building kernel based VOIP system ?. This is not new but we are going to go through it here. I am assuming Linux as an operating system. The Linux kernel is about core and modules (micro kernel + loadable modules). You might not touch the core but you might need to build a module that support your VOIP system in the kernel for performance purposes. The new module supposed to do VOIP jobs (filtering, QoS, protection, media relay). There are already some useful kernel modules that can support your system like NATing, IPv6ing, and so on . Use them!
In this article i will just introduce what you need to know to follow this series of articles: how to compile and install a new, fresh and clean Linux kernel and what you need to know to compile and install a new kernel module.
We will not touch the current running kernel but building a new one, install it, boot from it, write a new module, add it to the kernel and test it. You need to be very careful when you work in the kernel.
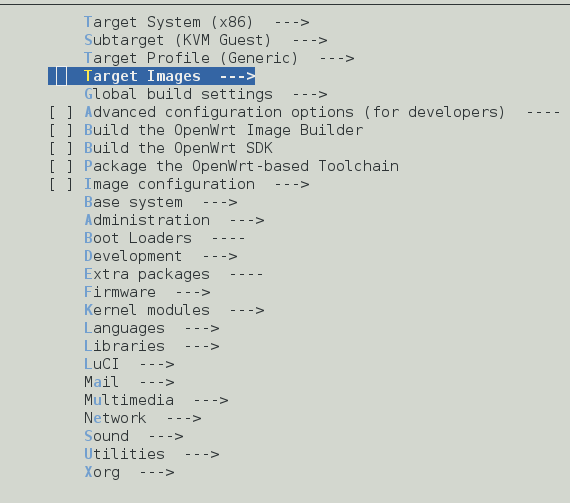
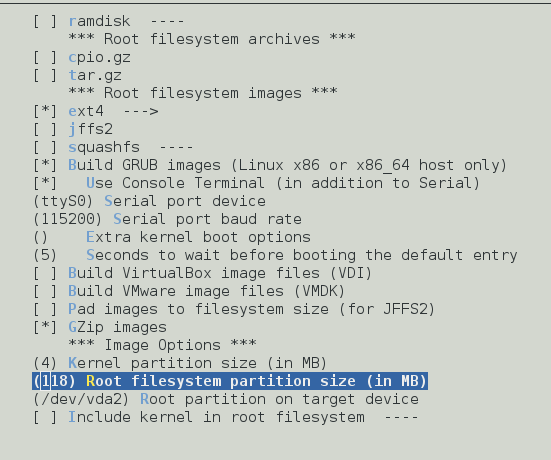
Compilation and Installation Steps
This is a traditional common way to all Linux distributions to compile and install a Linux kernel:
Download the source:
I will work on the kernel 3.19.5 as an example. For other versions, go to https://kernel.org/pub/linux/kernel and see the list there.
# wget -c https://kernel.org/pub/linux/kernel/v3.x/linux-3.19.5.tar.gz
Decompress the gz file and go to the directory “linux-3.19.5”:
# tar -xzvf linux-3.19.5.tar.gz
# cd linux-3.19.5
Configure the kernel:
Fresh configuration: traditional way: # make menuconfig or the modern way: # make nconfig
Note: To detect memory leaks in the kernel modules, you can use the tool ‘kmemleak’. To use it, you need to compile the kernel with ‘CONFIG_DEBUG_KMEMLEAK’ option enabled. Enable it as following: make menuconfig –> ‘kernel Hacking’ –> ‘Memory Debugging’ –> ‘Kernel Memory Leak Detector’. Enable this option and do save. You can check this file “/sys/kernel/debug/kmemleak” while testing.
You can use the config file of the current running kernel. In Fedora this file exists as /boot/config-$(KernelName). For example: /boot/config-3.19.5-100.fc20.x86_64. Then update it with ‘make menuconfig’ and save.
Compilation:
Prepare for the compilation: # make mrproper
Compile the kernel: # make
Install the compiled modules:
# make modules_install
The modules will be installed in /lib/modules/3.19.5/
Install the kernel: Now we want to copy and rename the image bzImage (arch/x86_64/boot/bzImage) to /boot + creating the initial RAM disk + creating the map/kernel symbols , and update the grub config file). This done by: # make install
After compiling and installing the kernel, we can boot from it (appear in the GRUB startup List).
Header Files needed to compile a new module:
If you want to build your own kernel module, you need to have the header files. Check the folder /lib/modules/3.19.5/build/ where 3.19.5 is the new kernel version.
The module is header and source files with Makefile file. When it is built we got .ko file. In the Makefile you need to specify the kernel source and the obj-m.
After building the module, it will be ready to be installed. You need to boot from the new kernel and do ‘modprob $ModuleName’
Again this article is just an introduction to this series. More information is coming next.
 The mobile push notification is a way to send a message to mobile devices via their services (e.g. Google, Apple, Kindle,…). The message reaches the operating system first through a shared channel between all applications running on the same device. Then it is forwarded to the target application listener and then the application can react upon this. The application needs to understand the format of the push message. The mobile needs to be connected to its service (e.g. Google GCM for Android devices, APN for Apple devices, ADM for Kindle devices) so it can receive the push messages on the shared channel. Any successfully authenticated third party server can send the push messages to its applications on the devices via the corresponding service which sends the messages directly to the devices. So the third party server needs to know the type of devices if it wants to support multiple types of devices.
The mobile push notification is a way to send a message to mobile devices via their services (e.g. Google, Apple, Kindle,…). The message reaches the operating system first through a shared channel between all applications running on the same device. Then it is forwarded to the target application listener and then the application can react upon this. The application needs to understand the format of the push message. The mobile needs to be connected to its service (e.g. Google GCM for Android devices, APN for Apple devices, ADM for Kindle devices) so it can receive the push messages on the shared channel. Any successfully authenticated third party server can send the push messages to its applications on the devices via the corresponding service which sends the messages directly to the devices. So the third party server needs to know the type of devices if it wants to support multiple types of devices.



{kind=link}